Adding ontology terms
- Author: Egon Willighagen (orcid:0000-0001-7542-0286)
- License: CC-BY 4.0
- Version: 1.0.3
- Source: https://github.com/enanomapper/tutorials/tree/master/Added%20ontology%20terms
This tutorial describes how terms can be added to the eNanoMapper ontology. Before walking through this tutorial, it is recommended to read the following documents:
- Article: eNanoMapper: harnessing ontologies to enable data integration for nanomaterial risk assessment
- Deliverable Report D2.1 Framework and Infrastructure for Ontology development, versioning and dissemination
- Deliverable Report D2.2 Ontology Content Types and Existing Community efforts
- Deliverable Report D2.3 Ontology initial release
- Deliverable Report D2.4 Ontology final release
A collection on ontology parts
The eNanoMapper ontology is mostly composed of other ontologies, with extensions here and there. The full list of ontologies it includes is:
- Adverse Outcome Pathways Ontology (AOP)
- BioAssay Ontology (BAO)
- Basic Formal Ontology (BFO)
- Cell Culture Ontology (CCONT)
- Chemical Entities of Biological Interest (CHEBI)
- Chemical Information Ontology (CHEMINF)
- Chemical Methods Ontology (CHMO)
- Experimental Factor Ontology (EFO)
- Environment Ontology (ENVO)
- FRBR-aligned Bibliographic Ontology (FABIO)
- Gene Ontology (GO)
- Human Physiology Simulation Ontology (HUPSON)
- Information Artifact Ontology (IAO)
- National Cancer Institute Thesaurus (NCIT)
- NanoParticle Ontology (NPO)
- Ontology of Adverse Events (OAE)
- Ontology of Biological and Clinical Statistics (OBCS)
- Ontology for Biomedical Investigations (OBI)
- Phenotype And Trait Ontology (PATO)
- Semanticscience Integrated Ontology (SIO)
- Unit Ontology (UO)
However, the eNanoMapper ontology does not use full ontologies, and there are reasons why that is essential:
- Most ontologies include bits from other ontologies; and,
- Some ontologies do not just have core concepts, but enumerate hundreds or thousands of instances.
The first reason has to do with maintainability. For example, what happens if two ontologies we import both import a third ontology, which import do we then take? eNanoMapper has chosen to always take the upstream version of the ontology. Besides resolving multiple imports of that third ontology, we now also have more control over which version we use. The situation is comparible to dependency resolution in software development.
The second reason has to do with controlling the FAIR-ness of the eNanoMapper ontology. For example, we want to ensure that terms important to the nanosafety field are not too hard to find. Therefore, the size of the ontology matters.
For these reasons, we select parts of ontologies (a full description of the design decision can be found in the eNanoMapper ontology publication). In order to perform this slicing we need a tool that can do this slicing and we need to instruct this slices which bits to keep.
The configuration file
Configuration file are used to define which parts of which ontologies are used. These configuration files can be found on GitHub. For each of the ontologies, two files are provided:
- A .props file
- A .iris file
The props file
The first “props” file is the one initially read by the Slimmer tool and looks like:
owl=https://raw.githubusercontent.com/enanomapper/aop-ontology/patch/hpoUpdate/aopo.owl
iris=aopo.iris
slimmed=http://purl.enanomapper.org/onto/external/aopo-slim.owl
It has three fields as explained in the following subsections
Source ontology file
The owl= line indicates where the OWL file of the ontology to be slimmed can be downloaded (this is normally an
upstream location, but a cached version in this particular case). It is exactly this OWL file that is loaded by the OWLAPI-based Slimmer utility, and slimmed.
Specifying the configuration
The iris= line indicates the configuration file is found locally which defines which IRIs are to be included and excluded in the slimmed version of the ontology. The syntax of the .iris file is discussed below.
The slimmed ontology file
The slimmed= line specifies the file name under which the resulting slimmed ontology is saved. It is this
file that is to be imported by the main eNanoMapper OWL file. That is, this URL is used for
owl:import statements in the eNanoMapper ontology, which is the used mechanism to include slimmed
ontology modules.
The iris file
The second configuration file defined the input to the slimming process and specifies what parts are meant to be kept. The format is a custom format specifically developed for our slimming needs.
The .iris file configures the slicing of the ontology. It specifies which classes or class tress to include and which parts to exclude. For each included class it can also specify a new classes it subclasses. Each line in this file defines one instruction: one addition or one removal.
For example:
+D(http://purl.bioontology.org/ontology/npo#NPO_1436):http://www.bioassayontology.org/bao#BAO_0000697 detection instrument
+D(http://purl.obolibrary.org/obo/IAO_0000030):http://www.bioassayontology.org/bao#BAO_0000179 endpoint
+D(http://purl.obolibrary.org/obo/OBI_0000070):http://www.bioassayontology.org/bao#BAO_0000015 bioassay
This configuration file uses a custom syntax which is briefly explained here. Here, the first line in the above example shows that the term detection instrument is imported (from the BAO ontology) and made a subclass of the NPO_1436 class from the NPO ontology.
The Syntax
Each instruction has the same structure, the same syntax, organized in layers:
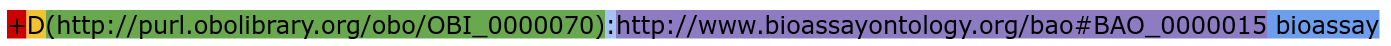
We can see here basically the five layers (red, yellow, green, purple, and blue) and in semi-colon (light blue) to separate two layers. If you consider that an ontology is often a hierarchical tree of terms, with one root node, spreading down, ending in leaf nodes, the above instruction could be visualized as this:
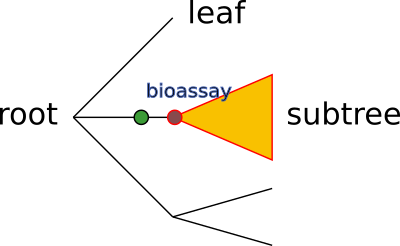
A more detailed description of each layer is introduced below.
Adding and removing (red layer)
By default it removes all content. The first character indicates if the something needs to be included (+) or excluded from a previously defined inclusion (-).
Selections up and down (yellow layer)
The second layer indicates with a single character (U or D) whether a whole upper (U) or down (D) tree should be included or excluded (as defined by the first layer). This layer is optional and if not given then a single term is added. Second, the U operation is not currently used by eNanoMapper.
An example of a command without the U or D operator that adds a single term:
+(http://www.bioassayontology.org/bao#BAO_0003009):http://purl.bioontology.org/ontology/npo#NPO_1709 LDH assay
This example reorganizes an existing term of the NPO into a location under a BAO term.
Which term to include (purple layer) and a label or reason (blue layer)
After the colon the URI of the resource is given to be in- or excluded, followed by a user-oriented comment. This comment can be the label of the item, a general comment, or the reason for adding it. It is not used in the slimming process.
Where to add it in the eNanoMapper ontology (green layer)
Finally, before the colon and in brackets an optional superclass of this resource can be specified, possibly from other ontologies. The instruction indicating where in an ontology a term is to be added is used a lot. As the comment in this instruction shows, it can be used to move terms in different places in the ontology. For example, we can move a nanoparticle term from the ChEBI ontology to a place in a selected (slimmed) subtree of the NPO:
+(http://purl.bioontology.org/ontology/npo#NPO_1384):http://purl.obolibrary.org/obo/CHEBI_50831 relocate platinum nanoparticle
Adding terms
Adding terms to the eNanoMapper ontology is basically equivalent to making changes or adding such configuration files. If the ontology already exists, then you basically change the content of the iris file. If you need a new ontology from which you want to include terms, then you need to create a new combination of a props and an iris file. This is explained in the next sections.
Adding a term from an already used ontology
When you identified the term you want to add in an ontology that already is used by the eNanoMapper ontology (see this list), you basically need to identify the following information:
- What is the IRI of the term?
- Is it just that single term, or also parent or child terms?
- Where in the eNanoMapper ontology should your selection show up?
That last question should be carefully considered, taking the hierarchy of the ontology into account. For example, moving a term below some concept from the BFO under a different concept from the BFO only works out well if one of the BFO concepts is a subclass of the other.
An example of adding a single term
The simplest addition one can make to the ontology, is adding a single term. One basically then only needs to know which term to add, and the parent of the term in the eNanoMapper ontology. We then do not have to worry about pulling in a full subtree, which may introduce a large set of terms and bloat the ontology.
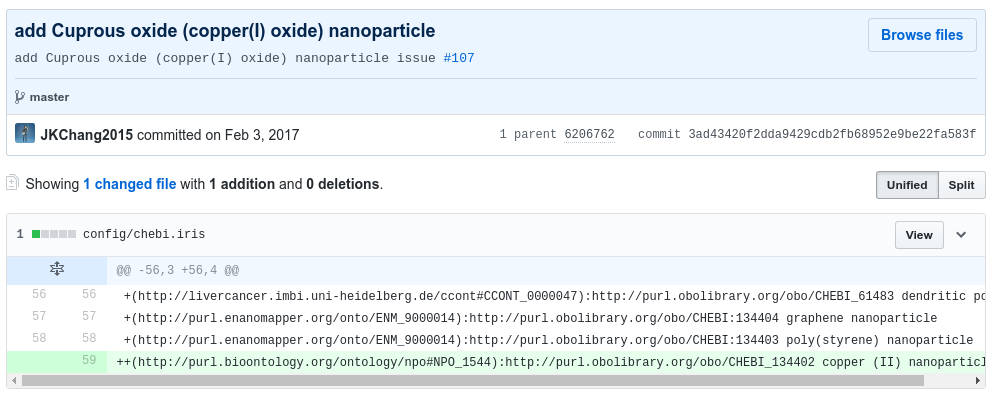
The following screenshot shows a commit that adds a terms (cuprous oxide nanoparticle) from an ontology that already is used (CHEBI) and puts it in as a child of term another already used ontology (NPO):
An example of adding a term and all children
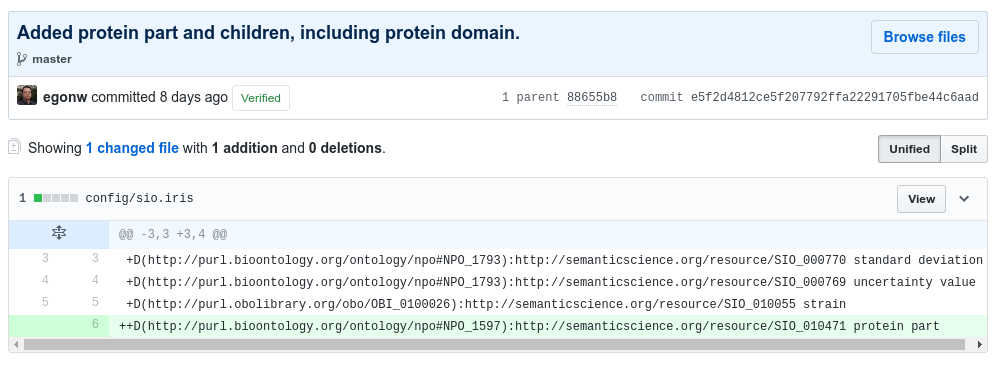
The following screenshot shows a commit that adds a term (protein part) from an ontology that already is used (SIO):
An example of a new term, unavailable from any ontology
The last example given here is adding a term that does not exist in any ontology. In this situation we can just create a new term. The hardest part is to select a new term identifier (IRI) for the term that is not used already.
New terms are defined as Web Ontology Language (OWL) classes, and should have an identifier (already said), label, and superclass. It may look like (actual example, see commit below):
For example:
<owl:Class rdf:about="http://purl.enanomapper.org/onto/ENM_9000238">
<rdfs:subClassOf rdf:resource="http://purl.bioontology.org/ontology/npo#NPO_354"/>
<rdfs:label xml:lang="en">Mitsui MWCNT-7</rdfs:label>
</owl>
The above example adds a term with the IRI http://purl.enanomapper.org/onto/ENM_9000238. The local part
ENM_9000238 must be unique. When creating a new IRI, it is important to ensure it is.
Some people may prefer adding this term with Protégé (which has the advantage that it will figure out an unused identifier) but it can be just as well added with a plain text editor. Ideally, the editor understands XML Schema, allowing you to be warned of the XML/OWL syntax is not correct, e.g. the Kate editor.
These additions are put in files in the internal folder. Several ontologies already have terms that should, ultimately, be incorporated in that upstream ontology.
The following screenshot shows an example existing commit that adds a term (Mitsui MWCNT-7) as child to a term from an ontology that already is used (NPO):
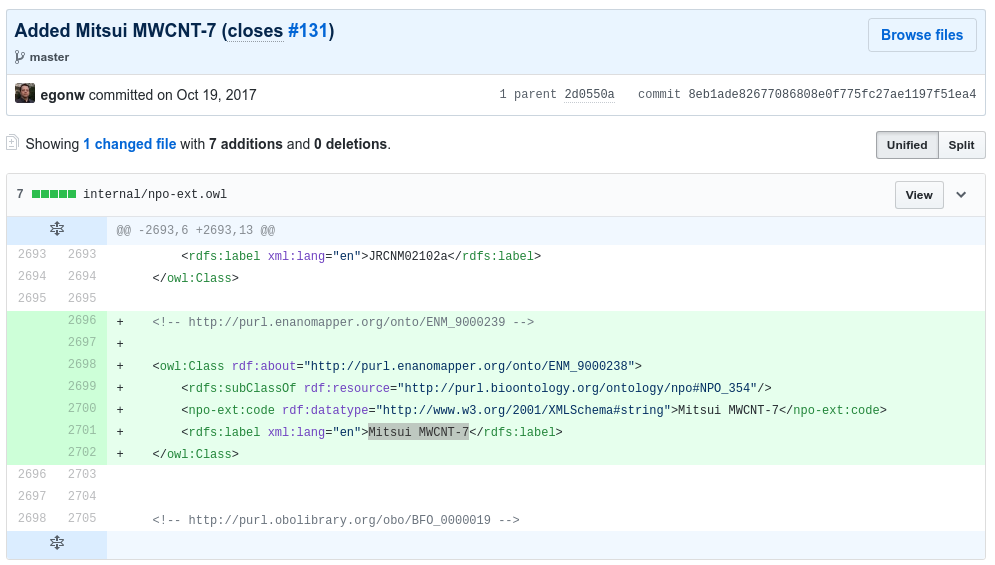
Adding a term from an ontology that is not yet used
Adding a term from an ontology that is not yet used is not that different from the adding the terms from an already used ontology: we just have to make sure that the ontology is “used”. That means, we have to ensure the following:
- Create a .props and .iris file (as described earlier)
- Set up a Jenkins job for the slimming
- Include the new ontology in the eNanoMapper ontology
The first step is to create the .props and .iris file. The latter can even be empty at the start, or contain a single term to be added. The combination of the following two commits show how the FABIO ontology was recently added:
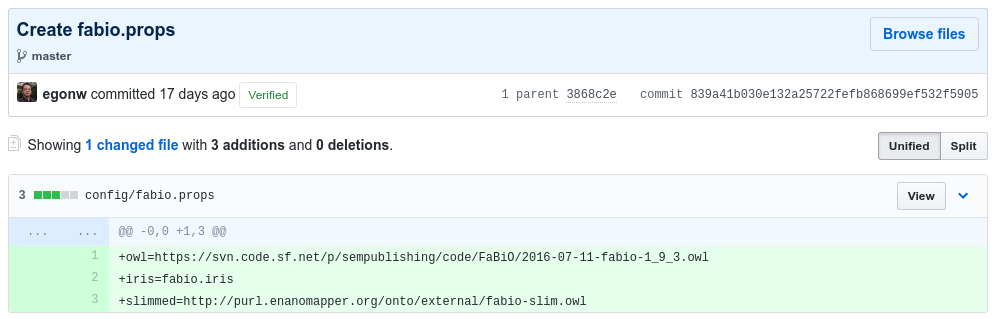
and
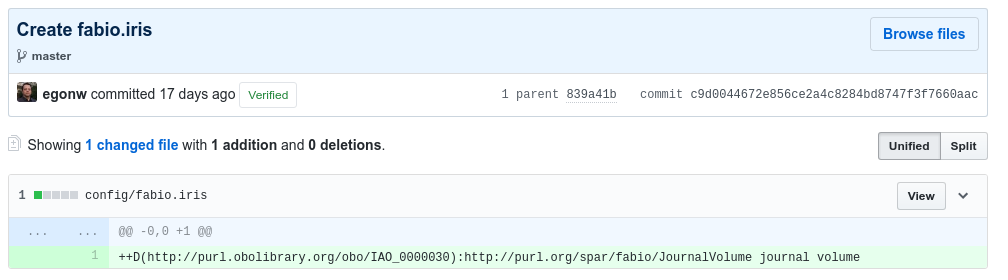
Setting up Jenkins can be done by everyone from the eNanoMapper project, but the reader can also file an issue here to request adding an ontology, or do that as part of the pull request that adds the above two files. In fact, do not worry too much about this step, as this is a responsibility of the ontology release manager (currently Egon Willighagen).
The final step is to ensure the ontology is listed (owl:include) in the ontology, which is
done by adding a line to the
enanomapper-auto-dev.owl
file, which looks like:
<owl:imports rdf:resource="http://purl.enanomapper.net/onto-dev/AOP/ws/aopo-slim.owl"/>
Monitoring the building
The building of the eNanoMapper ontology is monitored by a Jenkins server hosted by the BiGCaT group, part of the NUTRIM research school at Maastricht University. Login access to this server is set up by In Silico Toxicology Gmbh and uses the OpenTox Authentication and Authorisation framework. This section gives some pointers how this build server allows you to monitor
Checking the building
Jenkins is a continuous build server, hosted at https://jenm.bigcat.maastrichtuniversity.nl/. Here, jobs run for each of the included ontologies:
Checking the outcome
The final check to be performed is to see if the term actually shows up on the ontology browsers (BioPortal, Ontology Lookup Service, AberOWL, etc). For that, please check Browsing the eNM ontology with BioPortal, AberOWL and Protégé tutorial.
How a Slimming job is set up
As indicated earlier, each of the ontologies is slimmed by a separate Jenkins job. Basically, for each of the ontologies the following steps are taken, here for the AOP ontology. The first step is to delete old files and download the OWL file of the ontology (which it really should get from the .props file, but currently still is hard coded):
rm -f *.owl
rm -f *.owl.*
wget -O aopo.owl https://raw.githubusercontent.com/enanomapper/aop-ontology/patch/hpoUpdate/aopo.owl
The next step makes sure to get the latest copies from the ontologies repository of the .prop and .iris files,
followed by calling the Slimmer tool, which automatically detects the .props file in the current (.)
directory:
rm -f aopo.props*
rm -f aopo.iris*
wget https://raw.githubusercontent.com/enanomapper/ontologies/master/config/aopo.props
wget https://raw.githubusercontent.com/enanomapper/ontologies/master/config/aopo.iris
java -cp ../Slimmer/target/slimmer-0.0.1-SNAPSHOT-jar-with-dependencies.jar com.github.enanomapper.Slimmer .
Acknowledgments
This tutorial was written as part of the OpenRiskNet and NanoCommons projects. OpenRiskNet (Grant Agreement 731075) and NanoCommons (Grant Agreement 731032) are projects funded by the European Commission within Horizon2020 Programme